파이썬 코드
https://github.com/JHWannabe/self-taught_machine_learning_code.git
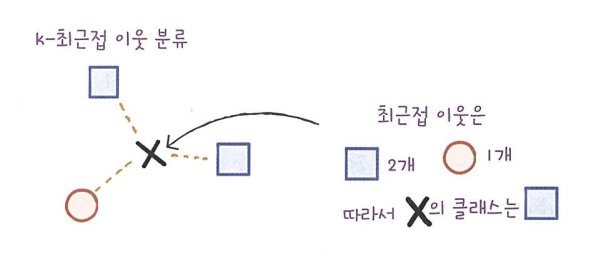
3.1 k - 최근접 이웃 회귀
회귀(Regression) : 임의의 어떤 숫자를 예측하는 문제

농어 길이와 무게를 산점도로 표시한 예제

결정계수(R^2)
사이킷런에서 k-최근접 이웃 회귀 알고리즘을 구현한 클래스는 KNeighborsRegressor이다.
이 클래스의 사용법은 KNeighborsClassifier와 매우 비슷하다.


분류의 경우는 테스트 세트에 있는 샘플을 정확하게 분류한 개수의 비율(정확도)이다.
회귀의 경우에는 결정계수라는 점수로 부르거나, R^2 라고도 부른다.

만약 타깃의 평균 정도를 예측하는 수준이라면 결정계수는 0에 가까워지고, 예측이 타깃에 아주 가까워지면 1에 가까운 값이 된다.
타깃과 예측한 값 사이의 차이를 구해 볼 수도 있다.
사이킷런은 sklearn.metrics 패키지 아래 여러 가지 측정 도구를 제공한다. 이 중에서 mean_absolute_error는 타깃과 예측의 절댓값 오차를 평균하여 반환한다.

과대적합 vs 과소적합
- 과대적합(overfitting): 훈련 세트에만 잘 맞는 모델이라 테스트 세트와 나중에 실전에 투입하여 새로운 샘플에 대한 예측을 만들 때 잘 동작하지 않을 것이다.
- 과소적합(underfitting): 모델이 너무 단순하여 훈련 세트에 적절히 훈련되지 않은 경우이다. 또는 훈련 세트와 테스트 세트의 크기가 매우 작아서 생기는 경우이다.
3.2 선형 회귀
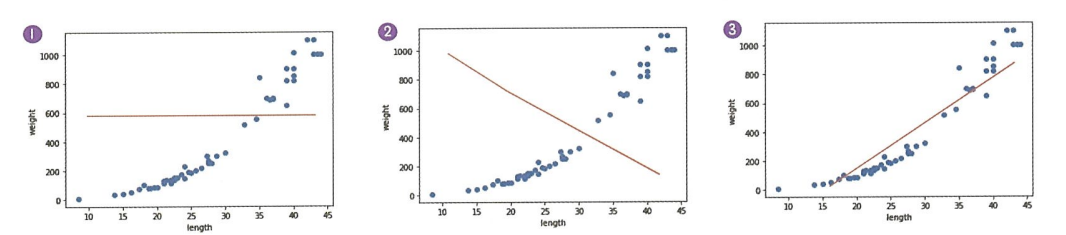
그래프 1은 모든 농어의 무게를 하나로 예측한다. 여기에서 직선의 위치가 훈련 세트의 평균에 가까우면 결정계수는 0에 가깝다.
그래프 2는 완전히 반대로 예측한다. 이런 경우에는 결정계수는 음수가 될 수 있다.
그래드 3이 가장 그럴싸한 직선이다.
사이킷런은 sklearn.linear_model 패키지 아래에 LinearRegression 클래스로 선형 회귀 알고리즘을 구현해 놓았다.


y = ax + b라고 할 때 coef_는 a에 해당하는 계수이고, intercepet_는 b에 해당하는 가중치이다. 여기서 coef_와 intercept_를 머신러닝 알고리즘이 찾은 값이라는 의미로 모델 파라미터라고 부른다.
다항 회귀

3.3 특성 공학과 규제
다중 회귀(Multiple Regression): 여러 개의 특성을 사용한 선형 회귀
1개의 특성을 사용하면 직선, 2개의 특성을 사용하면 평면이 된다.

특성 공학(feature engineering): 기존의 특성을 사용해 새로운 특성을 뽑아내는 작업


사이킷런의 변환기
사이킷런은 특성을 만들거나 전처리하기 위한 다양한 클래스를 제공한다. 이런 클래스를 변환기라고 한다.



규제 (Regularization)
- 머신러닝 모델이 훈련 세트를 너무 과도하게 학습하지 못하도록 훼방하는 것
- 릿지(Ridge)와 라쏘(Lasso)
- sklearn.linear_model 패키지 안에 있다.
1. 릿지(Ridge) 회귀


alpha 값을 0.001에서 100까지 10배씩 늘려가며 릿지 회귀 모델을 훈련한 다음 훈련 세트와 테스트 세트의 점수를 파이썬 리스트에 저장한다.


릿지는 비교적 효과가 좋아 널리 사용하는 규제 방법이다.
2. 라쏘(Lasso) 회귀





라쏘는 계수 값을 아예 0으로 만들 수 있다.
'AI 입문 > Machine Learning' 카테고리의 다른 글
| 6장 - 비지도 학습 (0) | 2022.11.30 |
|---|---|
| 5장 - 트리 알고리즘 (0) | 2022.11.25 |
| 4장 - 다양한 분류 알고리즘 (0) | 2022.11.11 |


