12.1 텍스트 생성
12.1.1 시퀀스 생성을 위한 딥러닝 모델의 간단한 역사
2014년 후반 머신 러닝 공동체에서도 소수의 사람만이 LSTM이란 용어를 알았다.
순환 네트워크를 사용하여 시퀀스 데이터를 성공적으로 생성한 애플리케이션은 2016년이 되어서야 주류가 되기 시작했다.
2000년대 후반과 2010년대 초반에 알렉스 그레이브스(Alex Graves)는 순환 네트워크를 사용하여 시퀀스 데이터를 생성하는 데 아주 중요한 선구적인 일을 했다. 특히 2013년에 펜 위치를 기록한 시계열 데이터를 사용하여 순환 네트워크와 완전 연결 네트워크를 혼합한 네트워크로 사람이 쓴 것 같은 손글씨를 생성했으며, 이 작업이 전환점이 되었다. 때맞추어 등장한 특별한 이 신경망 애플리케이션은 꿈을 꾸는 컴퓨터를 상상하게 만들었고, 필자가 케라스를 개발할 때 많은 영감을 주었다.
2015년에서 2017년 사이에 순환 신경망은 텍스트와 대화 생성, 음악 생성, 음성 합성에 성공적으로 사용되었다.
그다음 2017~2018년 즈음에 트랜스포머 아키텍처가 자연어 처리 지도 학습 작업뿐만 아니라 시퀀스 생성 모델, 특히 언어 모델링(단어 수준의 텍스트 생성)에서 순환 신경망을 압도하기 시작했다. 가장 잘 알려진 생성 트랜스포머의 예는 1,750억 개의 파라미터를 가진 텍스트 생성 모델인 GPT-3다. 이 모델은 OpenAI가 디지털로 공개된 대부분의 책과 위키피디아를 포함하여 전체 인터넷을 상당 부분 크롤링한 엄청나게 큰 텍스트 말뭉치에서 훈련했다. GPT-3는 거의 모든 주제에 대해 그럴듯한 텍스트 문장을 생성하는 능력 때문에 뉴스 헤드라인을 장식했다. 가장 더운 AI 여름이라고 말할 만큼 짧은 기간에 걸쳐 큰 관심을 이끌어 냈다.
12.1.2 시퀀스 데이터를 어떻게 생성할까?
딥러닝에서 시퀀스 데이터를 생성하는 일반적인 방법은 이전 토큰을 입력으로 사용해서 시퀀스의 다음 1개 또는 몇 개의 토큰을 (트랜스포머나 RNN으로) 예측하는 것이다. 이전 토큰들이 주어졌을 때 다음 토큰의 확률을 모델링할 수 있는 네트워크를 언어 모델(language model)이라고 부른다.
언어 모델을 훈련하고 나면 이 모델에서 샘플링을 할 수 있다(새로운 시퀀스를 생성다). 초기 텍스트 문자열을 주입하고(조건 데이터(conditioning data)라고 부른다) 새로운 글자나 단어를 생성한다(한 번에 여러 개의 토큰을 생성할 수도 있다). 생성된 출력은 다시 입력 데이터로 추가됩니다. 이 과정을 여러 번 반복한다. 이런 반복을 통해 모델이 훈련한 데이터 구조가 반영된 임의의 길이를 가진 시퀀스를 생성할 수 있다.

12.1.3 샘플링 전략의 중요성
텍스트를 생성할 때 다음 문자를 선택하는 방법이 아주 중요하다. 단순한 방법은 항상 가장 높은 확률을 가진 글자를 선택하는 탐욕적 샘플링(greedy sampling)이다. 이 방법은 반복적이고 예상 가능한 문자열을 만들기 때문에 논리적인 언어처럼 보이지 않는다.
다음 단어를 확률 분포에서 샘플링하는 과정에 무작위성을 주입하는 방법이다. 이를 확률적 샘플링(stochastic sampling)이라고 부른다(머신 러닝에서 확률적(stochastic)이란 뜻은 무작위(random)하다는 뜻). 이런 방식을 사용할 경우 어떤 단어가 문장의 다음 단어가 될 확률이 0.3이라면, 모델이 30% 정도는 이 단어를 선택한다. 탐욕적 샘플링을 확률적 샘플링으로 설명할 수도 있다. 한 단어의 확률이 1이고 나머지 단어는 모두 0인 확률 분포를 가지는 경우다.
모델의 소프트맥스 출력은 확률적 샘플링에 사용하기 좋다. 이따금 샘플링될 것 같지 않은 단어가 선택된다. 훈련 데이터에는 없지만 실제 같은 새로운 문장을 만들기 때문에 더 흥미롭게 보이는 문장이 만들어지고 이따금 창의성을 보이기도 한다. 이 전략에는 한 가지 문제가 있다. 샘플링 과정에서 무작위성의 양을 조절할 방법이 없다.
왜 무작위성이 크거나 작아야 할까? 극단적인 경우를 생각해 보죠. 균등 확률 분포에서 다음 단어를 추출하는 완전한 무작위 샘플링이 있다. 모든 단어의 확률은 같다. 이 구조는 무작위성이 최대이다. 다른 말로 하면 이 확률 분포는 최대의 엔트로피를 가진다. 당연하게 흥미로운 것들을 생산하지 못한다. 반대의 경우 탐욕적 샘플링도 무작위성이 없기 때문에 흥미로운 것을 전혀 만들지 못한다. 탐욕적 샘플링의 확률 분포는 최소의 엔트로피를 가진다.
모델의 소프트맥스 출력인 ‘실제’ 확률 분포에서 샘플링하는 것은 이 두 극단의 중간에 위치해 있다. 중간 지점에는 시도해 볼 만한 더 높거나 낮은 엔트로피가 많다. 작은 엔트로피는 예상 가능한 구조를 가진 시퀀스를 생성한다 반면 높은 엔트로피는 놀랍고 창의적인 시퀀스를 만든다. 생성 모델에서 샘플링을 할 때 생성 과정에 무작위성의 양을 바꾸어 시도해 보는 것이 좋다. 흥미는 매우 주관적이므로 최적의 엔트로피 값을 미리 알 수 없기 때문이다. 얼마나 흥미로운 데이터를 생성할 것인지는 결국 사람이 판단해야 한다.
샘플링 과정에서 확률의 양을 조절하기 위해 소프트맥스 온도(softmax temperature)라는 파라미터를 사용한다. 이 파라미터는 샘플링에 사용되는 확률 분포의 엔트로피를 나타낸다. 얼마나 놀라운 또는 예상되는 단어를 선택할지 결정한다. temperature 값이 주어지면 다음과 같이 가중치를 적용하여 (모델의 소프트맥스 출력인) 원본 확률 분포에서 새로운 확률 분포를 계산한다.

높은 온도는 엔트로피가 높은 샘플링 분포를 만들어 더 놀랍고 생소한 데이터를 생성한다. 반면낮은 온도는 무작위성이 낮기 때문에 예상할 수 있는 데이터를 생산한다.

12.1.4 케라스를 사용한 텍스트 생성 모델 구현
IMDB 영화 리뷰 데이터셋을 계속 사용하여 이전에 본 적 없는 영화 리뷰를 생성하는 방법을 학습시켜 본다. 따라서 이 언어 모델은 일반적인 영어를 모델링하는 것이 아니라 이런 영화 리뷰의 스타일과 주제를 모델링할 것이다.
데이터 준비




트랜스포머 기반의 시퀀스-투-시퀀스 모델
몇 개의 초기 단어가 주어지면 문장의 다음 단어에 대한 확률 분포를 예측하는 모델을 훈련한다. 이 모델을 훈련할 때 초기 문장을 주입하고, 다음 단어를 샘플링하여 이 문장에 추가하는 식으로 짧은 문단을 생성할 때까지 반복한다.
10장의 온도 예측 문제에서 했던 것처럼 N개 단어의 시퀀스를 입력으로 받아 N + 1번째 단어를 예측하는 모델을 훈련한다. 하지만 시퀀스 생성 관점으로 보았을 때 여기에는 몇 가지 이슈가 있다.
첫째, 이 모델은 N개의 단어로 예측을 만드는 방법을 학습하지만 N개보다 적은 단어로 예측을 시작할 수 있어야 한다. 그렇지 않으면 비교적 긴 시작 문장(여기에서는 N=100개 단어)을 사용해야 하는 제약이 생긴다. 10장에서는 이런 요구 사항이 없었다.
둘째, 훈련에 사용하는 많은 시퀀스는 중복되어 있다. N=4일 때를 예로 들어 보면, “A complete sentence must have, at minimum, three things: a subject, verb and an object”는 다음과 같은 훈련 시퀀스를 만다.
이런 두 이슈를 해결하기 위해 시퀀스-투-시퀀스 모델을 사용한다. 즉, 단어 N개의 시퀀스(0에서 N까지)를 모델에 주입하고 한 스텝 다음의 시퀀스(1에서 N + 1까지)를 예측한다. 코잘 마스킹(causal masking)을 사용하여 어떤 인덱스 i에서 모델은 0에서 i까지 단어만 사용해서 i + 1번째 단어를 예측하도록 만든다. 이는 대부분 중복되지만 N개의 다른 문제를 해결하도록 모델을 동시에 훈련한다는 의미다. 즉, 1 <= i <= N인 단어의 시퀀스에서 다음 단어를 예측한다. 생성 단계에서는 하나의 단어만 모델에 전달하더라도 다음 단어에 대한 확률 분포를 만들 수 있을 것이다.


12.1.5 가변 온도 샘플링을 사용한 텍스트 생성 콜백
콜백을 사용하여 에포크가 끝날 때마다 다양한 온도로 텍스트를 생성한다. 모델이 수렴하면서 생성된 텍스트가 어떻게 발전하는지와 온도가 샘플링 전략에 미치는 영향을 확인할 수 있다.



12.1.6 정리
- 이전의 토큰이 주어지면 다음 토큰(들)을 예측하는 모델을 훈련하여 시퀀스 데이터를 생성할 수 있다.
- 텍스트의 경우 이런 모델을 언어 모델이라고 부릅니다. 단어 또는 글자 단위 모두 가능하다.
- 다음 토큰을 샘플링할 때 모델이 만든 출력에 집중하는 것과 무작위성을 주입하는 것 사이에 균형을 맞추어야 한다.
- 이를 위해 소프트맥스 온도 개념을 사용합니다. 항상 다양한 온도를 실험해서 적절한 값을 찾는다.
12.2 딥드림
딥드림(DeepDream)은 합성곱 신경망이 학습한 표현을 사용하여 예술적으로 이미지를 조작하는 기법이다. 2015년 여름 구글이 카페(Caffe) 딥러닝 라이브러리를 사용하여 구현한 것을 처음 공개했다. 딥드림이 생성한 몽환적인 사진은 순식간에 인터넷에 센세이션을 일으켰다.
딥드림 알고리즘은 9장에서 소개한 컨브넷을 거꾸로 실행하는 컨브넷 필터 시각화 기법과 거의 동일하다. 컨브넷 상위 층에 있는 특정 필터의 활성화를 극대화하기 위해 컨브넷의 입력에 경사 상승법을 적용했다. 몇 개의 사소한 차이를 빼면 딥드림도 동일한 아이디어를 사용한다.
- 딥드림에서는 특정 필터가 아니라 전체 층의 활성화를 최대화한다. 한꺼번에 많은 특성을 섞어 시각화한다.
- 빈 이미지나 노이즈가 조금 있는 입력이 아니라 이미 가지고 있는 이미지를 사용한다. 그 결과 기존 시각 패턴을 바탕으로 이미지의 요소들을 다소 예술적인 스타일로 왜곡시킨다.
- 입력 이미지는 시각 품질을 높이기 위해 여러 다른 스케일(옥타브(octave)라고 부릅니다)로 처리한다.
12.2.1 케라스 딥드림 구현









12.2.2 정리
- 딥드림은 네트워크가 학습한 표현을 기반으로 컨브넷을 거꾸로 실행하여 입력 이미지를 생성한다.
- 재미있는 결과가 만들어지고, 때로는 환각제 때문에 시야가 몽롱해진 사람이 만든 이미지 같기도 한다.
- 이 과정은 이미지 모델이나 컨브넷에 국한되지 않는다. 음성, 음악 등에도 적용될 수 있다.
12.3 뉴럴 스타일 트랜스퍼
딥드림 이외에 딥러닝을 사용하여 이미지를 변경하는 또 다른 주요 분야는 뉴럴 스타일 트랜스퍼(neural style transfer)다. 2015년 여름 리온 게티스(Leon Gatys) 등이 소개했다. 뉴럴 스타일 트랜스퍼 알고리즘은 처음 소개된 이후에 많이 개선되었고 여러 변종이 생겼다. 스마트폰의 사진 앱에도 쓰인다. 이 절에서는 간단하게 원본 논문에 소개한 방식에 집중한다.
뉴럴 스타일 트랜스퍼는 타깃 이미지의 콘텐츠를 보존하면서 참조 이미지의 스타일을 타깃 이미지에 적용한다.

텍스처(texture) 생성과 밀접하게 연관된 스타일 트랜스퍼의 아이디어는 2015년 뉴럴 스타일 트랜스퍼가 개발되기 이전에 이미 이미지 처리 분야에서 오랜 역사를 가지고 있다. 딥러닝을 기반으로 한 스타일 트랜스퍼 구현은 고전적인 컴퓨터 비전 기법으로 만든 것과는 비견할 수 없는 결과를 제공한다. 창조적인 컴퓨터 비전 애플리케이션 분야에 새로운 르네상스를 열었다.
스타일 트랜스퍼 구현 이면에 있는 핵심 개념은 모든 딥러닝 알고리즘의 핵심과 동일하다. 목표를 표현한 손실 함수를 정의하고 이 손실을 최소화한다. 여기에서 원하는 것은 다음과 같다. 참조 이미지의 스타일을 적용하면서 원본 이미지의 콘텐츠를 보존하는 것이다. 콘텐츠와 스타일을 수학적으로 정의할 수 있다면 최소화할 손실 함수는 다음과 같을 것이다.

12.3.1 컨텐츠 손실
앞서 배웠듯이 네트워크에 있는 하위 층의 활성화는 이미지에 관한 국부적인 정보를 담고 있다. 반면 상위 층의 활성화일수록 점점 전역적이고 추상적인 정보를 담게 된다. 다른 방식으로 생각하면 컨브넷 층의 활성화는 이미지를 다른 크기의 콘텐츠로 분해한다고 볼 수 있다. 컨브넷 상위 층의 표현을 사용하면 전역적이고 추상적인 이미지 콘텐츠를 찾을 수 있을 것이다.
타깃 이미지와 생성된 이미지를 사전 훈련된 컨브넷에 주입하여 상위 층의 활성화를 계산한다. 이 두 값 사이의 L2 노름이 콘텐츠 손실로 사용하기에 좋다. 상위 층에서 보았을 때 생성된 이미지와 원본 타깃 이미지를 비슷하게 만들 것이다. 컨브넷의 상위 층에서 보는 것이 입력 이미지의 콘텐츠라고 가정하면 이미지의 콘텐츠를 보존하는 방법으로 사용할 수 있다.
12.3.2 스타일 손실
콘텐츠 손실은 하나의 상위 층만 사용한다. 게티스 등이 정의한 스타일 손실은 컨브넷의 여러 층을 사용한다. 하나의 스타일이 아니라 참조 이미지에서 컨브넷이 추출한 모든 크기의 스타일을 잡아야 한다. 게티스 등은 층의 활성화 출력의 그람 행렬(Gram matrix)을 스타일 손실로 사용했다. 그람 행렬은 층의 특성 맵들의 내적(inner product)이다. 내적은 층의 특성 사이에 있는 상관관계를 표현한다고 이해할 수 있다. 이런 특성의 상관관계는 특정 크기의 공간적인 패턴 통계를 잡아낸다. 경험에 비추어 보았을 때 이 층에서 찾은 텍스처에 대응된다.
스타일 참조 이미지와 생성된 이미지로 층의 활성화를 계산한다. 스타일 손실은 그 안에 내재된 상관관계를 비슷하게 보존하는 것이 목적이다. 결국 스타일 참조 이미지와 생성된 이미지에서 여러 크기의 텍스처가 비슷하게 보이도록 만든다.
요약하면 사전 훈련된 컨브넷을 사용하여 다음 손실들을 정의할 수 있다.
- 콘텐츠를 보존하기 위해 원본 이미지와 생성된 이미지 사이에서 상위 층의 활성화를 비슷하게 유지한다. 이 컨브넷은 원본 이미지와 생성된 이미지에서 동일한 것을 보아야 한다.
- 스타일을 보존하기 위해 저수준 층과 고수준 층에서 활성화 안에 상관관계를 비슷하게 유지한다. 특성의 상관관계는 텍스처를 나타낸다. 따라서 생성된 이미지와 스타일 참조 이미지는 여러 크기의 텍스처를 공유할 것이다.
12.3.3 케라스로 뉴럴 스타일 트랜스퍼 구현하기
뉴럴 스타일 트랜스퍼는 사전 훈련된 컨브넷 중 어떤 것을 사용해서도 구현할 수 있다. 여기에서는 게티스 등이 사용한 VGG19 네트워크를 사용한다. VGG19는 5장에서 소개한 VGG16 네트워크의 변종으로 합성곱 층이 3개 더 추가되었다.
일반적인 과정은 다음과 같다.
- 스타일 참조 이미지, 베이스 이미지(base image), 생성된 이미지를 위해 VGG19의 층 활성화를 동시에 계산하는 네트워크를 설정한다.
- 세 이미지에서 계산한 층 활성화를 사용하여 앞서 설명한 손실 함수를 정의한다. 이 손실을 최소화하여 스타일 트랜스퍼를 구현할 것이다.
- 손실 함수를 최소화할 경사 하강법 과정을 설정한다.


VGG19 네트워크를 준비해 본다. 딥드림 예제와 마찬가지로 사전 훈련된 컨브넷을 사용하여 중간층의 활성화를 반환하는 특성 추출 모델을 만들겠다. 이번에는 모델에 있는 모든 층을 사용다.

콘텐츠 손실을 정의해 본다. VGG19 컨브넷의 상위 층은 베이스 이미지와 생성된 이미지에서 동일한 것을 보아야 다.

다음은 스타일 손실이다. 유틸리티 함수를 사용하여 입력 행렬의 그람 행렬을 계산한다. 이 행렬은 원본 특성 행렬의 상관관계를 기록한 행렬이다.

두 손실에 하나를 더 추가한다. 생성된 이미지의 픽셀을 사용하여 계산하는 총 변위 손실(total variation loss)이다. 이는 생성된 이미지가 공간적인 연속성을 가지도록 도와주며 픽셀의 격자 무늬가 과도하게 나타나는 것을 막아 준다. 이를 일종의 규제 항으로 해석할 수 있다.

최소화할 손실은 이 세 손실의 가중치 평균이다. 콘텐츠 손실은 block5_conv2 층 하나만 사용해서 계산한다. 스타일 손실을 계산하기 위해서는 하위 층과 상위 층에 걸쳐 여러 층을 사용한다. 그리고 마지막에 총 변위 손실을 추가한다.
사용하는 스타일 참조 이미지와 콘텐츠 이미지에 따라 content_weight 계수(전체 손실에 기여하는 콘텐츠 손실의 정도)를 조정하는 것이 좋다. content_weight가 높으면 생성된 이미지에 타깃 콘텐츠가 더 많이 나타나게 된다.


마지막으로 경사 하강법 단계를 설정한다. 게티스의 원래 논문에서는 L-BFGS 알고리즘을 사용하여 최적화를 수행했다. 하지만 텐서플로에는 이 알고리즘이 없기 때문에 대신 SGD 옵티마이저로 미니 배치 경사 하강법을 수행한다. 여기에서 처음으로 학습률 스케줄(learning rate schedule)이라는 옵티마이저 기능을 활용해 본다. 이를 사용하여 매우 높은 값(100)에서 최종적으로 아주 낮은 값(약 20)까지 점진적으로 학습률을 줄인다. 이렇게 하면 훈련 초기에는 빠른 속도로 진행되며 최소 손실에 가까울수록 점점 더 조심스럽게 훈련이 진행된다.
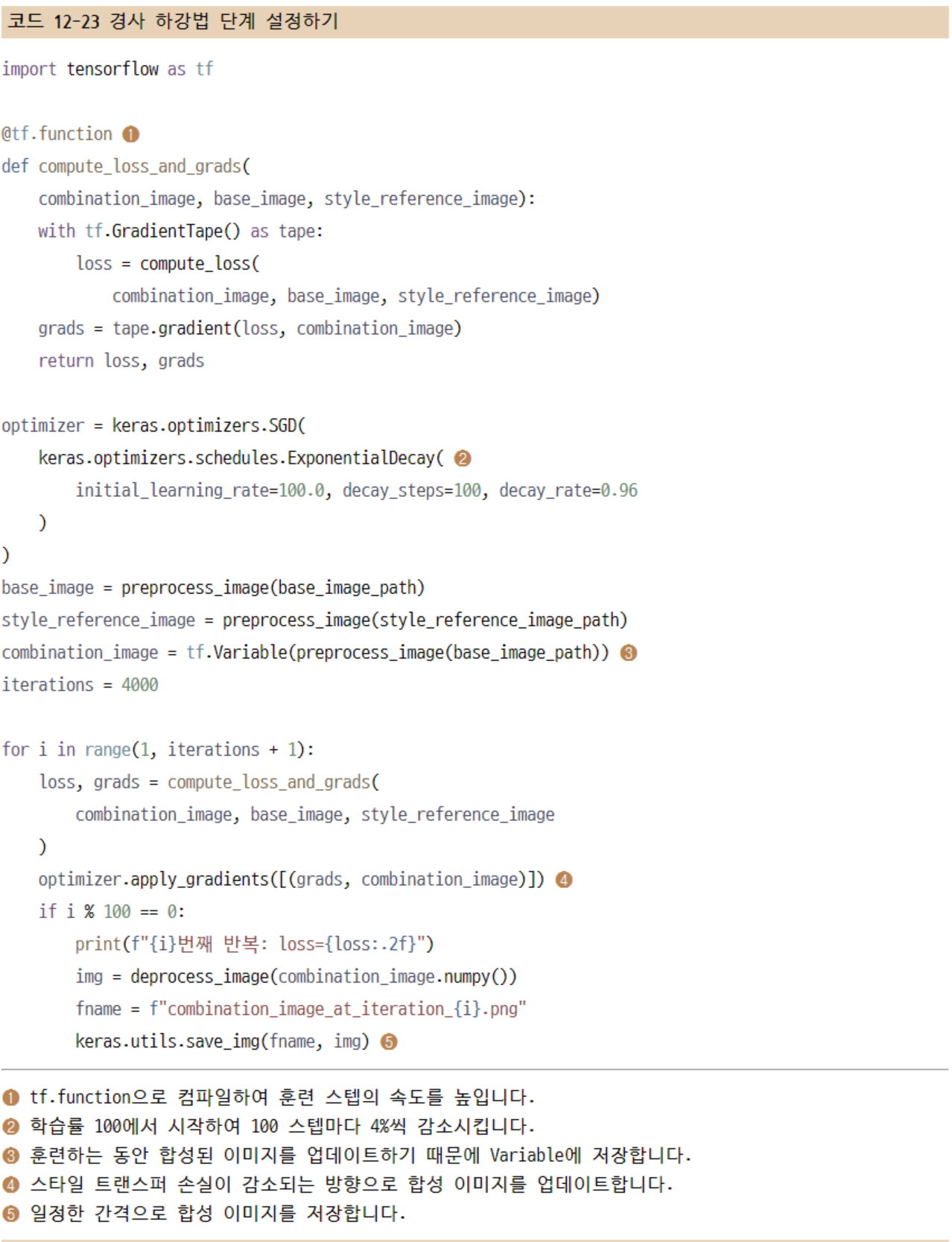
12.3.4 정리
- 스타일 트랜스퍼는 참조 이미지의 스타일을 적용하면서 타깃 이미지의 콘텐츠를 보존하여 새로운 이미지를 만드는 방법이다.
- 콘텐츠는 컨브넷 상위 층의 활성화에서 얻을 수 있다.
- 스타일은 여러 컨브넷 층의 활성화 안에 내재된 상관관계에서 얻을 수 있다.
- 딥러닝에서는 사전 훈련된 컨브넷으로 손실을 정의하고 이 손실을 최적화하는 과정으로 스타일 트랜스퍼를 구성할 수 있다.
- 이런 기본 아이디어에서 출발하여 다양한 변종과 개선이 가능하다.
12.4 변이형 오토인코더를 사용한 이미지 생성
오늘날 창조적인 AI에서 가장 인기 있고 성공적인 애플리케이션은 이미지 생성이다. 잠재 시각 공간(latent visual space)을 학습하고 이 공간에서 샘플링하여 실제 사진에서 보간된 완전히 새로운 이미지를 만든다.
12.4.1 이미지의 잠재 공간에서 샘플링하기
이미지 생성의 핵심 아이디어는 각 포인트가 실제와 같은 이미지로 매핑될 수 있는 저차원 잠재 공간(딥러닝의 다른 모든 것과 마찬가지로 이는 벡터 공간이다)의 표현을 만드는 것이다. 잠재 공간의 한 포인트를 입력으로 받아 이미지(픽셀의 그리드)를 출력하는 모듈을 (GAN에서는) 생성자(generator) 또는 (VAE에서는) 디코더(decoder)라고 부른다. 잠재 공간을 학습하면 여기에서 포인트 하나를 샘플링할 수 있다. 그다음 이미지 공간으로 매핑하여 이전에 본 적 없는 이미지를 생성한다. 이런 새로운 이미지는 훈련 이미지 사이에 위치한다.

12.4.2 이미지 변형을 위한 개념 벡터
11장에서 단어 임베딩을 다룰 때 이미 개념 벡터(concept vector)에 대한 아이디어를 얻었다. 이 아이디어와 동일하다. 잠재 공간이나 임베딩 공간이 주어지면 이 공간의 어떤 방향은 원본 데이터의 흥미로운 변화를 인코딩한 축일 수 있다. 예를 들어 얼굴 이미지에 대한 잠재 공간에 웃음 벡터가 있을 수 있다. 잠재 공간의 z 포인트가 어떤 얼굴의 임베딩된 표현이라면 잠재 공간의 z + s 포인트는 같은 얼굴이 웃고 있는 표현을 임베딩한 것이다. 이런 벡터를 찾아내면 이미지를 잠재 공간에 투영해서 의미 있는 방향으로 이 표현을 이동한 후 이미지 공간으로 디코딩하여 복원하면 변형된 이미지를 얻을 수 있다. 기본적으로 이미지 공간에서 독립적으로 변화가 일어나는 모든 차원이 개념 벡터다. 얼굴이라면 안경을 쓰고 벗거나 남자 얼굴을 여자 얼굴로 바꾸는 등의 벡터를 발견할 수 있다.
12.4.3 변이형 오토인코더
생성 모델의 한 종류로 개념 벡터를 사용하여 이미지를 변형하는 데 아주 적절하다. 오토인코더는 입력을 저차원 잠재 공간으로 인코딩한 후 디코딩하여 복원하는 네트워크다. 변이형 오토인코더는 딥러닝과 베이즈 추론(Bayesian inference)의 아이디어를 혼합한 오토인코더의 최신 버전이다.
고전적인 오토인코더는 이미지를 입력받아 인코더 모듈을 사용하여 잠재 벡터 공간으로 매핑한다. 그다음 디코더 모듈을 사용해서 원본 이미지와 동일한 차원으로 복원하여 출력한다. 오토인코더는 입력 이미지와 동일한 이미지를 타깃 데이터로 사용하여 훈련한다. 다시 말해 오토인코더는 원본 입력을 재구성하는 방법을 학습한다. 코딩(coding)(인코더의 출력)에 여러 제약을 가하면 오토인코더가 더 흥미로운 또는 덜 흥미로운 잠재 공간의 표현을 학습한다. 일반적으로 코딩이 저차원이고 희소(0이 많은)하도록 제약을 가한다. 이런 경우 인코더는 입력 데이터의 정보를 적은 수의 비트에 압축하기 위해 노력한다.

현실적으로 이런 전통적인 오토인코더는 특별히 유용하거나 구조화가 잘된 잠재 공간을 만들지 못한다. 압축도 아주 뛰어나지 않다. 이런 이유 때문에 시대의 흐름에서 대부분 멀어졌다. VAE는 오토인코더에 약간의 통계 기법을 추가하여 연속적이고 구조적인 잠재 공간을 학습하도록 만들었다. 결국 이미지 생성을 위한 강력한 도구로 탈바꿈되었다.
입력 이미지를 잠재 공간의 고정된 코딩으로 압축하는 대신 VAE는 이미지를 어떤 통계 분포의 파라미터로 변환한다. 이는 입력 이미지가 통계적 과정을 통해 생성되었다고 가정하여 인코딩과 디코딩하는 동안 무작위성이 필요하다는 것을 의미한다. VAE는 평균과 분산 파라미터를 사용하여 이 분포에서 무작위로 하나의 샘플을 추출한다. 이 샘플을 디코딩하여 원본 입력으로 복원한다. 이런 무작위한 과정은 안정성을 향상하고 잠재 공간 어디서든 의미 있는 표현을 인코딩하도록 만든다. 즉, 잠재 공간에서 샘플링한 모든 포인트는 유효한 출력으로 디코딩된다.

기술적으로 보면 VAE는 다음과 같이 작동한다.
- 인코더 모듈이 입력 샘플 input_img를 잠재 공간의 두 파라미터 z_mean과 z_log_var로 변환한다.
- 입력 이미지가 생성되었다고 가정한 잠재 공간의 정규 분포에서 포인트 z를 z = z_mean + exp(0.5 * z_log_var) * epsilon처럼 무작위로 샘플링한다. epsilon은 작은 값을 가진 랜덤 텐서다.
- 디코더 모듈은 잠재 공간의 이 포인트를 원본 입력 이미지로 매핑하여 복원한다.
epsilon이 무작위로 만들어지기 때문에 input_img를 인코딩한 잠재 공간의 위치(z_mean)에 가까운 포인트는 input_img와 비슷한 이미지로 디코딩될 것이다. 이는 잠재 공간을 연속적이고 의미 있는 공간으로 만들어 준다. 잠재 공간에서 가까운 2개의 포인트는 아주 비슷한 이미지로 디코딩될 것이다. 잠재 공간의 이런 저차원 연속성은 잠재 공간에서 모든 방향이 의미 있는 데이터 변화의 축을 인코딩하도록 만든다. 결국 잠재 공간은 매우 구조적이고 개념 벡터로 다루기에 적합해진다.
VAE의 파라미터는 2개의 손실 함수로 훈련한다. 디코딩된 샘플이 원본 입력과 동일하도록 만드는 재구성 손실(reconstruction loss)과 잠재 공간을 잘 형성하고 훈련 데이터에 과대적합을 줄이는 규제 손실(regularization loss)다.

그다음 재구성 손실과 규제 손실을 사용해서 모델을 훈련할 수 있다. 규제 손실로는 일반적으로 인코더 출력의 분포를 0을 중심으로 균형 잡힌 정규 분포로 이동시키는 식(쿨백-라이블러 발산(Kullback–Leibler divergence))을 사용한다. 이는 인코더가 모델링하는 잠재 공간의 구조에 대한 합리적인 가정을 제공한다.
12.4.4 케라스로 VAE 구현하기
MNIST 숫자를 생성할 수 있는 VAE를 구현해 본다. 이 모델은 세 부분으로 구성된다.
- 인코더 네트워크는 실제 이미지를 잠재 공간의 평균과 분산으로 변환한다.
- 샘플링 층은 이런 평균과 분산을 받아 잠재 공간에서 랜덤한 포인트를 샘플링한다.
- 디코더 네트워크는 잠재 공간의 포인트를 이미지로 변환한다.







12.4.5 정리
- 딥러닝으로 이미지 데이터셋에 대한 통계 정보를 담은 잠재 공간을 학습하여 이미지를 생성할 수 있다. 잠재 공간에서 포인트를 샘플링하고 디코딩하면 이전에 본 적 없는 이미지를 생성한다. 이를 수행하는 주요 방법은 VAE와 GAN이다.
- VAE는 매우 구조적이고 연속적인 잠재 공간의 표현을 만든다. 이런 이유로 잠재 공간 안에서 일어나는 모든 종류의 이미지 변형 작업에 잘 맞다. 다른 얼굴로 바꾸기, 찌푸린 얼굴을 웃는 얼굴로 변형하기 등이다. 잠재 공간을 가로질러 이미지가 변환하는 잠재 공간 기반의 애니메이션에도 잘 맞다. 시작 이미지가 연속적으로 다른 이미지로 부드럽게 바뀌는 것을 볼 수 있다.
- GAN은 실제 같은 단일 이미지를 생성할 수 있지만 구조적이고 연속적인 잠재 공간을 만들지 못한다.
12.5 생성적 적대 신경망 소개
GAN은 생성된 이미지가 실제 이미지와 통계적으로 거의 구분되지 않도록 강제하여 아주 실제 같은 합성 이미지를 생성한다.
GAN을 직관적으로 이해하는 방법은 가짜 피카소 그림을 만드는 위조범을 생각하는 것이다. 처음에 위조범은 형편없이 위조한다. 진짜 피카소 그림과 위조품을 섞어서 그림 판매상에게 보여 준다. 판매상은 각 그림이 진짜인지 평가하고 어떤 것이 피카소 그림 같은지 위조범에게 피드백을 준다. 위조범은 자신의 화실로 돌아가 새로운 위조품을 준비한다. 시간이 지남에 따라 위조범은 피카소의 스타일을 모방하는 데 점점 더 능숙해진다. 그림 판매상은 위조품을 구분하는 데 점점 더 전문가가 된다. 결국 아주 훌륭한 피카소 위조품을 만들어 낼 것이다.
위조범 네트워크와 전문가 네트워크가 바로 GAN이다. 두 네트워크는 상대를 이기기 위해 훈련한다. GAN의 네트워크 2개는 다음과 같다.
- 생성자 네트워크(generator network): 랜덤 벡터(잠재 공간의 무작위한 포인트)를 입력으로 받아 이를 합성된 이미지로 디코딩한다.
- 판별자 네트워크(discriminator network)(또는 적대 네트워크(adversary network)): 이미지(실제 또는 합성 이미지)를 입력으로 받아 훈련 세트에서 온 이미지인지, 생성자 네트워크가 만든 이미지인지 판별한다.
생성자 네트워크는 판별자 네트워크를 속이도록 훈련한다. 훈련이 계속될수록 점점 더 실제와 같은 이미지를 생성하게 된다. 실제 이미지와 구분할 수 없는 인공적인 이미지를 만들어 판별자 네트워크가 두 이미지를 동일하게 보도록 만든다. 한편 판별자 네트워크는 생성된 이미지가 실제인지 판별하는 기준을 높게 설정하면서 생성자의 능력 향상에 적응해 간다. 훈련이 끝나면 생성자는 입력 공간에 있는 어떤 포인트를 그럴듯한 이미지로 변환한다. VAE와 달리 이 잠재 공간은 의미 있는 구조를 보장하지 않다. 특히 이 공간은 연속적이지 않다.

놀랍게도 GAN은 최적화의 최솟값이 고정되지 않은 시스템이다. 이 책에서 다루는 어떤 훈련 설정과도 다르다. 보통 경사 하강법은 고정된 손실 공간에서 언덕을 내려오는 방법이다. GAN에서는 언덕을 내려오는 매 단계가 조금씩 전체 공간을 바꾼다. 최적화 과정이 최솟값을 찾는 것이 아니라 두 힘 간의 평형점을 찾는 다이나믹 시스템이다. 이런 이유로 GAN은 훈련하기 어렵기로 유명하다. GAN을 만들려면 모델 구조와 훈련 파라미터를 주의 깊게 많이 조정해야 힌다.
12.5.1 GAN 구현 방법
GAN 구조는 다음과 같다.
- generator 네트워크는 (latent_dim,) 크기의 벡터를 (64, 64, 3) 크기의 이미지로 매핑한다.
- discriminator 네트워크는 (64, 64, 3) 크기의 이미지가 진짜일 확률을 추정하여 이진 값으로 매핑한다.
- 생성자와 판별자를 연결하는 gan 네트워크를 만든다. gan(x) = discriminator(generator (x))이다. 이 gan 네트워크는 잠재 공간의 벡터를 판별자의 평가로 매핑한다. 즉, 판별자는 생성자가 잠재 공간의 벡터를 디코딩한 것이 얼마나 현실적인지 평가한다.
- “진짜”/“가짜” 레이블과 함께 진짜 이미지와 가짜 이미지 샘플을 사용하여 판별자를 훈련한다. 일반적인 이미지 분류 모델을 훈련하는 것과 동일하다.
- 생성자를 훈련하려면 gan 모델의 손실에 대한 생성자 가중치의 그레이디언트를 사용한다. 이 말은 매 단계마다 생성자에 의해 디코딩된 이미지를 판별자가 “진짜”로 분류하도록 만드는 방향으로 생성자의 가중치를 이동한다는 뜻이다. 다른 말로 하면 판별자를 속이도록 생성자를 훈련한다.
12.5.2 훈련 방법
GAN을 훈련하고 튜닝하는 과정은 어렵기로 유명하다. 알아 두어야 할 몇 가지 유용한 기법이 있다.
- VAE 디코더에서 했던 것처럼 판별자에서 특성 맵을 다운샘플링하는 데 풀링 대신 스트라이드를 사용한다.
- 균등 분포가 아니고 정규 분포(가우스 분포)를 사용하여 잠재 공간에서 포인트를 샘플링한다.
- 무작위성은 모델을 견고하게 만든다. GAN 훈련은 동적 평형을 만들기 때문에 여러 방식으로 갇힐 가능성이 높다. 훈련하는 동안 무작위성을 주입하면 이를 방지하는 데 도움이 된다. 이를 위해 판별자 레이블에 랜덤 노이즈를 추가한다.
- 희소한 그레이디언트는 GAN 훈련을 방해할 수 있다. 딥러닝에서 희소성은 종종 바람직한 현상이지만 GAN에서는 그렇지 않다. 그레이디언트를 희소하게 만들 수 있는 것은 최대 풀링 연산과 relu 활성화 두 가지이다. 최대 풀링 대신 스트라이드 합성곱을 사용하여 다운샘플링을 하는 것이 좋다. 또 relu 활성화 대신 LeakyReLU 층을 사용해라. ReLU와 비슷하지만 음수의 활성화 값을 조금 허용하기 때문에 희소성이 다소 완화된다.
- 생성자에서 픽셀 공간을 균일하게 다루지 못하여 생성된 이미지에서 체스판 모양이 종종 나타난다. 이를 해결하기 위해 생성자와 판별자에서 스트라이드 Conv2DTranspose나 Conv2D를 사용할 때 스트라이드 크기로 나누어질 수 있는 커널 크기를 사용한다.
12.5.3 CelebA 데이터셋 준비하기




12.5.4 판별자
먼저 후보 이미지(진짜와 합성 이미지)를 입력으로 받고 두 클래스(‘생성된 이미지’ 또는 ‘훈련 세트에서 온 이미지’) 중 하나로 분류하는 discriminator 모델을 만든다. GAN에서 발생하는 많은 문제 중 하나는 생성자가 노이즈 같은 이미지를 생성하는 데에서 멈추는 것이다. 판별자에 드롭아웃을 사용하는 것이 해결 방법이 될 수 있으므로 여기에서 이를 적용해본다.

12.5.5 생성자
그다음 (훈련하는 동안 잠재 공간에서 무작위로 샘플링된) 벡터를 후보 이미지로 변환하는 generator 모델을 만들어 본다.

12.5.6 적대 네트워크
마지막으로 생성자와 판별자를 연결하여 GAN을 모델 구성합니다. 훈련할 때 이 모델은 생성자가 판별자를 속이는 능력이 커지도록 학습시킨다. 이 모델은 잠재 공간의 포인트를 “진짜” 또는 “가짜”의 분류 결정으로 변환한다. 훈련에 사용되는 타깃 레이블은 항상 ‘진짜 이미지’이다. 따라서 gan을 훈련하는 것은 discriminator가 가짜 이미지를 보았을 때 진짜라고 예측하도록 만들기 위해 generator의 가중치를 업데이트하는 것이다.
훈련 반복의 내용을 요약 정리해본다. 매 반복마다 다음을 수행한다.
- 잠재 공간에서 무작위로 포인트를 뽑는다(랜덤 노이즈).
- 이 랜덤 노이즈를 사용하여 generator에서 이미지를 생성한다.
- 생성된 이미지와 진짜 이미지를 섞는다.
- 진짜와 가짜가 섞인 이미지와 이에 대응하는 타깃을 사용하여 discriminator를 훈련한다. 타깃은 “진짜(실제 이미지일 경우)” 또는 “가짜(생성된 이미지일 경우)”이다.
- 잠재 공간에서 무작위로 새로운 포인트를 뽑는다.
- 이 랜덤 벡터를 사용하여 generator를 훈련한다. 모든 타깃은 “진짜”로 설정한다. 판별자가 생성된 이미지를 모두 “진짜 이미지”라고 예측하도록 생성자의 가중치를 업데이트한다. 결국 생성자는 판별자를 속이도록 훈련된다.




12.5.7 정리
- GAN은 생성자 네트워크와 판별자 네트워크가 연결되어 구성된다. 판별자는 생성자의 출력과 훈련 데이터셋에서 가져온 진짜 이미지를 구분하도록 훈련된다. 생성자는 판별자를 속이도록 훈련된다. 놀랍게도 생성자는 훈련 세트의 이미지를 직접 보지 않는다. 데이터에 관한 정보는 판별자에서 얻는다.
- GAN은 훈련하기 어렵다. GAN 훈련이 고정된 손실 공간에서 수행하는 단순한 경사 하강법 과정이 아니라 동적 과정이기 때문이다. GAN을 올바르게 훈련하려면 경험적으로 찾은 여러 기교를 사용하고 많은 튜닝을 해야 한다.
- GAN은 매우 실제 같은 이미지를 만들 수 있다. VAE와 달리 학습된 잠재 공간이 깔끔하게 연속된 구조를 가지지 않는다. 잠재 공간의 개념 벡터를 사용하여 이미지를 변형하는 등 실용적인 특정 애플리케이션에는 잘 맞지 않다.
12.6 요약
- 시퀀스-투-시퀀스 모델을 사용하여 한 번에 한 스텝씩 시퀀스 데이터를 생성할 수 있습니다. 텍스트 생성뿐만 아니라 음표 하나씩 음악을 생성하거나 다른 어떤 시계열 데이터를 생성하는 곳에 적용할 수 있습니다.
- 딥드림은 입력 공간에 경사 상승법을 적용하여 컨브넷 층 활성화를 최대화하는 식으로 동작합니다.
- 스타일 트랜스퍼 알고리즘에서는 경사 하강법을 통해 콘텐츠 이미지와 스타일 이미지를 연결하여 콘텐츠 이미지의 고수준 특성과 스타일 이미지의 국부적인 특징을 가진 이미지를 만듭니다.
- VAE와 GAN은 이미지의 잠재 공간을 학습하고 이 잠재 공간에서 샘플링하여 완전히 새로운 이미지를 만들 수 있는 모델입니다. 개념 벡터(concept vector)를 사용하여 이미지를 변형할 수도 있습니다.
'AI 입문 > Deep Learning' 카테고리의 다른 글
| 13장 - 실전 문제 해결을 위한 모범 사례 (0) | 2023.02.23 |
|---|---|
| 11장 - 텍스트를 위한 딥러닝 (1) | 2023.02.12 |
| 10장 - 시계열을 위한 딥러닝 (0) | 2023.02.08 |
| 9장 - 컴퓨터 비전을 위한 고급 딥러닝 (0) | 2023.01.22 |
| 8장 - 컴퓨터 비전을 위한 딥러닝 (2) | 2023.01.22 |



