9.1 세 가지 주요 컴퓨터 비전 작업
3개의 주요 컴퓨터 비전 작업
- 이미지 분류(image classification) : 이미지에 하나 이상의 레이블을 할당하는 것이 목표입니다.
- 이미지 분할(image segmentation): 이미지를 다른 영역으로 ‘나누’거나 ‘분할’하는 것이 목표입니다.
- 객체 탐지(object detection): 이미지에 있는 관심 객체 주변에 (바운딩 박스(bounding box)라고 부르는) 사각형을 그리는 것이 목표입니다.

이외에도 여러 가지 틈새 분야 작업
이미지 유사도 평가(image similarity scoring)(두 이미지가 시각적으로 얼마나 비슷한지 추정하기), 키포인트 감지(keypoint detection)(얼굴 특징과 같이 이미지에서 관심 속성을 정확히 짚어 내기), 포즈 추정(pose estimation), 3D 메시 추정(mesh estimation) 등
9.2 이미지 분할 예제
이미지 분할 : 모델을 사용하여 이미지 안의 각 픽셀에 클래스를 할당하는 것
ㄴ 이미지를 여러 다른 영역(‘배경’과 ‘전경’ 또는 ‘도로’, ‘자동차’, ‘보도’)으로 분할
- 시맨틱 분할(semantic segmentation): 각 픽셀이 독립적으로 ‘cat’과 같은 하나의 의미를 가진 범주로 분류됩니다. 이미지에 2개의 고양이가 있다면 이에 해당되는 모든 픽셀은 동일한 ‘cat’ 범주로 매핑됩니다.
- 인스턴스 분할(instance segmentation): 이미지 픽셀을 범주로 분류하는 것뿐만 아니라 개별 객체 인스턴스를 구분합니다. 이미지에 2개의 고양이가 있다면 인스턴스 분할은 ‘cat 1’과 ‘cat 2’를 2개의 별개 클래스로 다룹니다.

시맨틱 분할에 초점을 맞출 예정
ㄴ 주 피사체를 배경에서 분리하는 방법
Oxford-IIIT Pets 데이터셋(https://www.robots.ox.ac.uk/~vgg/data/pets/)을 사용
분할 마스크(segmentation mask)는 이미지 분할에서 레이블에 해당한다. 입력 이미지와 동일한 크기의 이미지고 컬러 채널은 하나다. 각 정수 값은 입력 이미지에서 해당 픽셀의 클래스를 나타내는데, 이 데이터셋의 경우 분할 마스크의 픽셀은
3개의 정수 값(1(전경), 2(배경), 3(윤곽)) 중 하나를 가집니다.





이 모델의 처음 절반은 이미지 분류에서 사용하는 컨브넷과 닮았다.
Conv2D 층을 쌓고 점진적으로 필터 개수를 늘린다. 이미지를 절반으로 세 번 다운샘플링(downsampling)하여 마지막 합성곱 층의 활성화 출력은 (25, 25, 256)으로 끝난다. 이 모델에서 처음 절반의 목적은 이미지를 작은 특성 맵으로 인코딩하는 것이다. 공간상의 각 위치(픽셀)는 원본 이미지에 있는 더 큰 영역에 대한 정보를 담고 있다. 이를 일종의 압축으로 이해할 수 있다.
이 모델의 처음 절반과 이전에 보았던 분류 모델 사이의 큰 차이점 하나는 다운샘플링 방식이다. 이전 장의 이미지 분류 컨브넷은 MaxPooling2D 층을 사용하여 특성 맵을 다운샘플링했다. 여기에서는 합성곱 층마다 스트라이드(stride)를 추가하여 다운샘플링한다. (8.1.1절의 ‘합성곱 스트라이드 이해하기’를 참고)
이 모델의 나머지 절반은 Conv2DTranspose 층을 쌓은 것이다. 다운샘플링이 아니라 특성 맵을 업샘플링(upsampling)하는 것이다.
(100, 100, 64) 크기의 입력을 Conv2D(128, 3, strides=2, padding="same") 층에 통과시키면 출력 크기는 (50, 50, 128)이 된다. 이 출력을 Conv2DTranspose(64, 3, strides=2, padding="same") 층에 통과시키면 원본과 동일한 (100, 100, 64) 크기가 출력된다.
따라서 Conv2D 층을 쌓아 입력을 (25, 25, 256) 크기의 특성 맵으로 압축한 후 Conv2DTranspose 층을 연속으로 적용하여 (200, 200, 3) 크기의 이미지를 다시 얻을 수 있습니다.


중간 즈음인 에포크 25 근처에서 과대적합이 시작되는 것을 볼 수 있다.
9.3 최신 ConvNet 아키텍쳐 패턴
모델의 아키텍처(architecture) : 모델을 만드는 데 사용된 일련의 선택
ㄴ 사용할 층, 층의 설정, 층을 연결하는 방법 등
ㄴ 이런 선택 모델의 가설 공간(hypothesis space)을 정의한다.
ㄴ 경사 하강법이 해결할 문제를 간단하게 만드는 것
- 잔차 연결(residual connection)
- 배치 정규화(batch normalization)
- 분리 합성곱(separable convolution)
9.3.1 모듈화, 계층화 그리고 재사용
복잡한 시스템을 단순하게 만들고 싶다면 일반적으로 적용할 수 있는 방법이 있다.
수프처럼 형태를 알아보기 힘든 복잡한 구조를 모듈화(modularity)하고, 모듈을 계층화(hierarchy)하고, 같은 모듈을 적절하게 여러 곳에서 재사용(reuse)(추상화(abstraction)의 다른 말)하는 것입니다. 이것이 MHR(Modularity-Hierarchy-Reuse) 공식이다.
효율적인 코드는 모듈화되고 계층적이며 동일한 것을 두 번 구현하지 않는다. 그 대신 재사용 가능한 클래스와 함수를 사용다. 이런 원칙에 따라 코드를 리팩터링하면 이를 ‘소프트웨어 아키텍처’를 수행했다고 말할 수 있다.
딥러닝 자체는 경사 하강법을 통한 연속적인 최적화에 이런 방법을 적용한 것뿐이다. 전통적인 최적화 기법(연속적인 함수 공간에 대한 경사 하강법)을 사용해서 탐색 공간을 모듈(층)로 구조화하여 깊게 계층을 구성한다(가장 단순한 것은 순서대로 쌓은 것). 여기에서 모든 것을 재사용할 수 있다(예를 들어 합성곱은 다른 공간 위치에서 동일한 정보를 재사용하는 것).
딥러닝 모델 아키텍처는 모듈화, 계층화, 재사용을 영리하게 활용하는 것이다.

계층 구조가 깊으면 특성 재사용과 이로 인한 추상화를 장려하기 때문에 본질적으로 좋다. 일반적으로 작은 층을 깊게 쌓은 모델이 큰 층을 얇게 쌓은 것보다 성능이 좋다. 하지만 그레이디언트 소실(vanishing gradient) 문제 때문에 층을 쌓을 수 있는 정도에 한계가 있다. 이런 문제가 첫 번째 핵심 아키텍처 패턴인 잔차 연결을 탄생시켰다.
9.3.2 잔차 연결 (residual connection)
그레이디언트 소실(vanishing gradient) 문제 : 함수 연결이 너무 깊으면 이 잡음이 그레이디언트 정보를 압도하기 시작하고 역전파가 동작하지 않게 된다. 즉, 모델이 전혀 훈련되지 않을 것이다.
ㄴ 해결 방법 : 연결된 각 함수를 비파괴적으로 만든다. 즉, 이전 입력에 담긴 잡음 없는 정보를 유지시킨다.
ㄴ 이를 구현하는 가장 쉬운 방법 → 잔차 연결
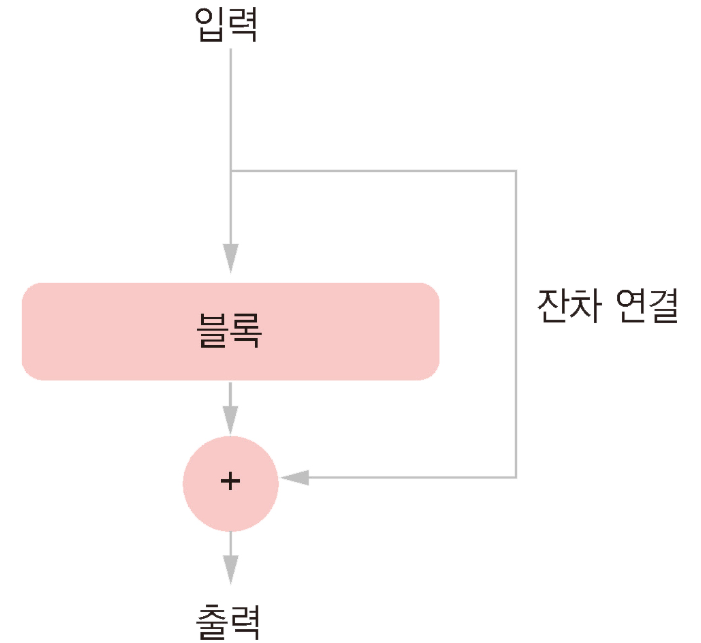




잔차 연결을 사용하면 그레이디언트 소실에 대해 걱정하지 않고 원하는 깊이의 네트워크를 만들 수 있다.
9.3.3 배치 정규화 (batch normalization)
정규화(normalization) : 머신 러닝 모델에 주입되는 샘플들을 균일하게 만드는 광범위한 방법
ㄴ 가장 일반적인 형태 : 데이터에서 평균을 빼서 데이터를 원점에 맞추고 표준 편차로 나누어 데이터의 분산을 1로 만드는 것. 즉, 데이터가 정규 분포를 따른다고 가정하고 이 분포를 원점에 맞추고 분산이 1이 되도록 조정한 것.
배치 정규화(batch normalization) : 훈련하는 동안 평균과 분산이 바뀌더라도 이에 적응하여 데이터를 정규화한다. 훈련하는 동안 현재 배치 데이터의 평균과 분산을 사용하여 샘플을 정규화한다.
배치 정규화의 주요 효과
- 잔차 연결과 매우 흡사하게 그레이디언트의 전파를 도와주는 것으로 보인다.
- 결국 더 깊은 네트워크를 구성할 수 있다.

이렇게 하는 이유는 배치 정규화가 입력 평균을 0으로 만들지만 relu 활성화 함수는 0을 기준으로 값을 통과시키거나 삭제하기 때문이다. 활성화 함수 이전에 정규화를 수행하면 relu 함수의 활용도가 극대화된다.
9.3.4 깊이별 분리 합성곱
깊이별 분리 합성곱(depthwise separable convolution) 층 : Conv2D를 대체하면서 더 작고(훈련할 모델 파라미터가 더 적고) 더 가볍고(부동 소수점 연산이 더 적고) 모델의 성능을 몇 퍼센트 포인트 높일 수 있는 층. (SeparableConv2D에 구현) 이 층은 입력 채널별로 따로따로 공간 방향의 합성곱을 수행한다. 그 다음 그림과 같이 점별 합성곱(pointwise convolution)(1×1 합성곱)을 통해 출력 채널을 합친다.

공간 특성의 학습과 채널 방향 특성의 학습을 분리하는 효과
깊이별 분리 합성곱은 일반 합성곱보다 훨씬 적은 개수의 파라미터를 사용하고 더 적은 수의 연산을 수행하면서 유사한 표현 능력을 가진다. 수렴이 더 빠르고 쉽게 과대적합되지 않는 작은 모델을 만든다. 이런 장점은 제한된 데이터로 밑바닥부터 작은 모델을 훈련할 때 특히 중요하다.
대규모 모델에 적용된 사례로는 케라스에 포함된 고성능 컨브넷인 Xception 구조의 기반으로 깊이별 분리 합성곱이 사용되었다.
9.3.5 Xception 유사 모델에 모두 적용하기
컨브넷 아키텍처 원칙
- 모델은 반복되는 층 블록으로 조직되어야 합니다. 블록은 일반적으로 여러 개의 합성곱 층과 최대 풀링 층으로 구성.
- 특성 맵의 공간 방향 크기가 줄어듦에 따라 층의 필터 개수는 증가해야 함.
- 깊고 좁은 아키텍처가 넓고 얕은 것보다 나음.
- 층 블록에 잔차 연결을 추가하면 깊은 네트워크를 훈련하는 데 도움이 됨.
- 합성곱 층 다음에 배치 정규화 층을 추가하면 도움이 될 수 있음.
- Conv2D 층을 파라미터 효율성이 더 좋은 SeparableConv2D 층으로 바꾸면 도움이 될 수 있음.


새로운 모델은 90.8%의 테스트 정확도 달성. (이전 장의 단순한 모델은 83.5% 달성)
ㄴ 아키텍처 모범 사례를 따르면 모델 성능에 즉각적이고 괄목할 만한 영향을 줄 수 있다!
이 시점에서 성능을 더 향상시키려면 모델의 파라미터를 체계적으로 튜닝해야 합니다. (13장에서 다룰 예정)
9.4 ConvNet이 학습한 것 해석하기
컴퓨터 비전 애플리케이션을 구축할 때 근본적인 문제는 해석 가능성(interpretability).
표현들을 시각화하고 해석하는 다양한 기법 3가지
- 컨브넷 중간층의 출력(중간층에 있는 활성화)을 시각화하기: 연속된 컨브넷 층이 입력을 어떻게 변형시키는지 이해하고 개별적인 컨브넷 필터의 의미를 파악하는 데 도움이 된다.
- 컨브넷 필터를 시각화하기: 컨브넷의 필터가 찾으려는 시각적인 패턴과 개념이 무엇인지 상세하게 이해하는 데 도움이 된다.
- 클래스 활성화에 대한 히트맵(heatmap)을 이미지에 시각화하기: 어떤 클래스에 속하는 데 이미지의 어느 부분이 기여했는지 이해하고 이미지에서 객체의 위치를 추정(localization)하는 데 도움이 된다.
9.4.1 중간 활성화 시각화
중간층의 활성화 시각화는 어떤 입력이 주어졌을 때 모델에 있는 여러 합성곱과 풀링 층이 반환하는 값을 그리는 것
(층의 출력을 종종 활성화 함수의 출력인 활성화(activation)라고 부름)
이 방법은 네트워크에 의해 학습된 필터들이 어떻게 입력을 분해하는지 보여 준다. 너비, 높이, 깊이(채널) 3개의 차원에 대해 특성 맵을 시각화하는 것이 좋다. 각 채널은 비교적 독립적인 특성을 인코딩하므로 특성 맵의 각 채널 내용을 독립적인 2D 이미지로 그리는 것이 괜찮은 방법이다.

9.4.2 컨브넷 필터 시각화하기
컨브넷이 학습한 필터를 조사하는 또 다른 간편한 방법은 각 필터가 반응하는 시각적 패턴을 그려 보는 것
빈 입력 이미지에서 시작해서 특정 필터의 응답을 최대화하기 위해 컨브넷 입력 이미지에 경사 상승법을 적용한다. 결과적으로 입력 이미지는 선택된 필터가 최대로 응답하는 이미지가 될 것이다.













9.4.3 클래스 활성화의 히트맵 시각화하기
이 방법은 이미지의 어느 부분이 컨브넷의 최종 분류 결정에 기여하는지 이해하는 데 유용하다.
분류에 실수가 있는 경우 컨브넷의 결정 과정을 ‘디버깅’하는 데 도움이 된다(모델 해석 가능성(model interpretability)이라고 부르는 분야). 또한, 이미지에 특정 물체가 있는 위치를 파악하는 데 사용할 수도 있다.











이 시각화 기법은 2개의 중요한 질문에 대한 답을 준다.
- 왜 네트워크가 이 이미지에 아프리카 코끼리가 있다고 생각하는가?
- 아프리카 코끼리가 사진 어디에 있는가?
특히 코끼리 새끼의 귀가 강하게 활성화 되었는데 아마도 네트워크가 아프리카 코끼리와 인도 코끼리의 차이를 구분하는 방법일 것이다.
9.5 요약
- 딥러닝으로 다룰 수 있는 3개의 주요 컴퓨터 비전 작업은 이미지 분류, 이미지 분할, 객체 탐지입니다.
- 최신 컨브넷 아키텍처의 모범 사례를 따르면 모델의 성능을 최대한 높이는 데 도움이 될 것입니다. 이런 모범 사례에는 잔차 연결, 배치 정규화, 깊이별 분리 합성곱이 포함됩니다.
- 컨브넷이 학습한 표현을 쉽게 분석할 수 있습니다. 컨브넷은 블랙박스가 아닙니다!
- 클래스 활성화 히트맵을 포함하여 컨브넷이 학습한 필터를 시각화할 수 있습니다.
'AI 입문 > Deep Learning' 카테고리의 다른 글
| 11장 - 텍스트를 위한 딥러닝 (1) | 2023.02.12 |
|---|---|
| 10장 - 시계열을 위한 딥러닝 (0) | 2023.02.08 |
| 8장 - 컴퓨터 비전을 위한 딥러닝 (0) | 2023.01.22 |
| 7장 - 케라스 완전 정복 (0) | 2023.01.15 |
| 6장 - 일반적인 머신 러닝 워크플로 (0) | 2023.01.14 |



