2장 - 신경망의 수학적 구성 요소
2.1 신경망과의 첫 만남


신경망이 훈련 준비를 마치기 위해서 컴파일 단계에 포함될 세 가지가 더 필요
1. 옵티마이저(optimizer): 성능을 향상시키기 위해 입력된 데이터를 기반으로 모델을 업데이트하는 메커니즘
2. 손실 함수(loss function): 훈련 데이터에서 모델의 성능을 측정하는 방법으로 모델이 옳은 방향으로 학습될 수 있도록 함
3. 훈련과 테스트 과정을 모니터링할 지표: 여기에서는 정확도만 고려




2.2 신경망을 위한 데이터 표현
스칼라(랭크-0 텐서) > 벡터(랭크-1 텐서) > 행렬(랭크-2 텐서) > 랭크-3 텐서와 더 높은 랭크의 텐서
핵심 속성
- 축의 개수(랭크): 예를 들어 랭크-3 텐서에는 3개의 축이 있고, 행렬에는 2개의 축이 있다. 넘파이나 텐서플로 같은 파이썬 라이브러리에서는 ndim 속성에 저장되어 있다.
- 크기(shape): 텐서의 각 축을 따라 얼마나 많은 차원이 있는지를 나타낸 파이썬의 튜플(tuple)이다. 예를 들어 앞에 나온 행렬의 크기는 (3, 5)이고 랭크-3 텐서의 크기는 (3, 3, 5)이다. 벡터의 크기는 (5, )처럼 1개의 원소로 이루어진 튜플이다. 배열 스칼라는 ()처럼 크기가 없다.
- 데이터 타입(파이썬 라이브러리에서는 보통 dtype이라고 부름): 텐서에 포함된 데이터의 타입이다. 예를 들어 텐서의 타입은 float16, float32, float64, uint8 등이 될 수 있다. 텐서플로에서는 string 텐서를 사용하기도 한다.
2.3 신경망의 톱니바퀴: 텐서 연산
텐서 연산: 심층 신경망이 학습한 모든 변환을 수치 데이터 텐서에 적용하는 연산 또는 함수
1. 원소별 연산(relu 함수와 덧셈)


2. 브로드캐스팅
naive_add는 동일한 크기의 랭크-2 텐서만 지원한다. 하지만 Dense 층에서는 랭크-2 텐서와 벡터를 더했다. 크기가 다른 두 텐서가 더해질 때는 어떻게 하는 것인가.
모호하지 않고 실행 가능하다면 작은 텐서가 큰 텐서의 크기에 맞추어 브로드캐스팅(broadcasting)된다. 이는 두 단계로 이뤄진다.
- 큰 텐서의 ndim에 맞도록 작은 텐서에 (브로드캐스팅 축이라고 부르는) 축이 추가된다.
- 작은 텐서가 새 축을 따라서 큰 텐서의 크기에 맞도록 반복된다.
3. 텐서 곱셈
텐서 곱셈 또는 점곱(dot product, *)는 가장 널리 사용되고 유용한 텐서 연산이다.
넘파이에서 텐서 곱셈은 np.dot 함수를 사용하여 수행한다.
4. 텐서 크기 변환
특정 크기에 맞게 열과 행을 재배열한다는 뜻이다. 자주 사용하는 특별한 크기 변환은 전치(transposition)이다.
2.4 신경망의 엔진: 그레디언트 기반 최적화
훈련은 다음과 같은 훈련 반복 루프(Training Loop) 안에서 일어난다. 손실이 충분히 낮아질 때까지 반복 루프 안에서 이런 단계가 반복된다.
- 훈련 샘플 x와 이에 상응하는 타깃 y_true의 배치를 추출한다.
- x를 사용하여 모델을 실행하고(정방향 패스(forward pass) 단계), 예측 y_pred를 구한다.
- y_pred와 y_true의 차이를 측정하여 이 배치에 대한 모델의 손실을 계산한다.
- 배치에 대한 손실이 조금 감소되도록 모델의 모든 가중치를 업데이트 한다.
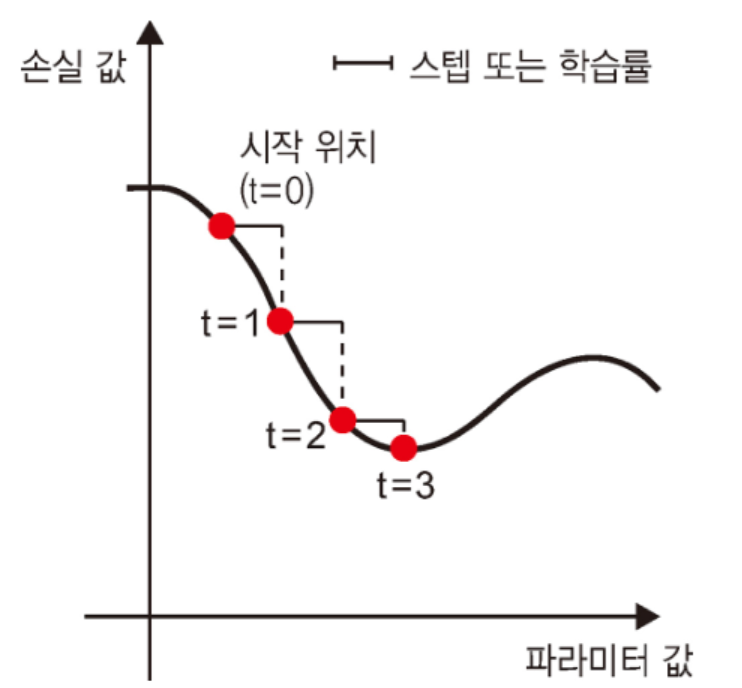
확률적 경사 하강법 (SGD)
- 훈련 샘플 x와 이에 상응하는 타깃 y_true의 배치를 추출한다.
- x로 모델을 실행하고 예측 y_pred를 구한다. (이를 정방향 패스라고 부른다.)
- 이 배치에서 y_pred와 y_true 사이의 오차를 측정하여 모델의 손실을 계산한다.
- 모델의 파라미터에 대한 손실 함수의 그레디언트를 계산한다. (이를 역방향 패스(backward pass)라고 부른다.)
- 그레디언트의 반대 방향으로 파라미터를 조금 이동시킨다. 학습률(learning rate)은 경사 하강법 과정의 속도를 조절하는 스칼라 값이다.
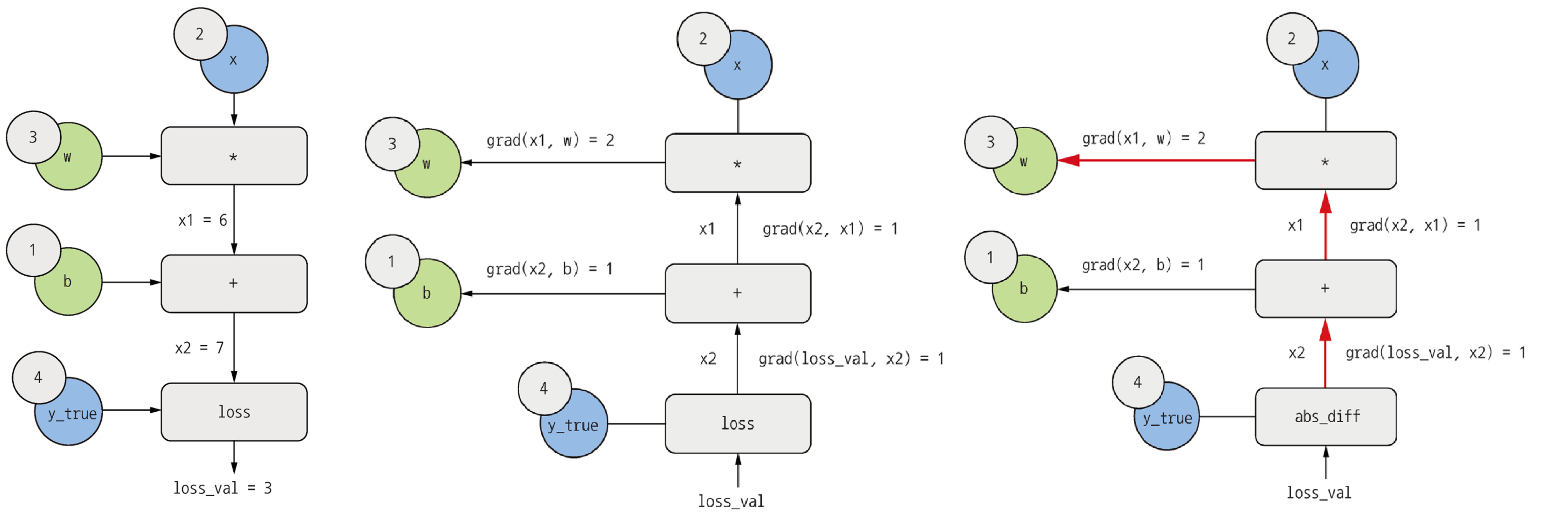
역전파 알고리즘 (Backpropagation Algorithm)
역전파 : 간단한 연산의 도함수를 사용해서 이런 기초적인 연산을 조합한 복잡한 연산의 그레디언트를 쉽게 계산하는 방법